5StepstoShipYourFirstAIApp—FromVercelPlaygroundtoAWSProduction

How I built MySleepyTale on Vercel, hit a latency wall, and moved to AWS with CloudFront + Lambda + S3 — a no-BS guide for first-time builders who ship on weekends.
It Started at 11 PM on a Friday
My daughter wouldn't sleep.
She'd rejected three books, two songs, and one very tired father's attempt at an improvised story about a flying elephant. "No, Papa. I want a NEW story. About a dragon. Who lives in a cloud. And his name is Biscuit."
I thought — what if an app could do this?
Not a generic story app. One that takes her exact weird request — dragon, cloud, name Biscuit — and returns a personalized bedtime story in seconds. With a soothing narration. With a soft illustration. Ready before she changes her mind (which gives me about 8 seconds).
That Friday night, I opened my laptop and started building. By Sunday evening, MySleepyTale was live. A real URL. Real users. A real app that generated AI bedtime stories on demand.
It took one weekend to build. It took three more weekends to make it actually fast enough for a toddler's patience.
This is that story.
 Where it all started — Vercel's zero-config deploys made the first weekend sprint possible
Where it all started — Vercel's zero-config deploys made the first weekend sprint possible
Step 1: Build Fast, Build Ugly — Vercel Is Your Weekend Lab
Here's something nobody tells first-time builders: your first deploy should embarrass you.
If it doesn't, you spent too long on it.
Vercel exists for exactly this moment. You have an idea at 11 PM on a Friday. By Saturday lunch, it should be live. Here's the path:
npx create-next-app@latest mysleepytale
cd mysleepytale
# write your one ugly page
git push origin main
# Vercel auto-deploys. You have a URL. Done.
For MySleepyTale v0.1, my entire app was:
- One
page.tsxwith a form (theme, character name, mood) - One API route that called OpenAI's API
- Zero styling (default Next.js template, yes the ugly one)
- Hardcoded prompts (I'll optimize later, I told myself)
The folder structure that got me live in 6 hours:
mysleepytale/
├── app/
│ ├── page.tsx ← form + display (everything in one file, judge me)
│ └── api/
│ └── generate/
│ └── route.ts ← the LLM call, ~40 lines of code
├── .env.local ← API keys (NEVER commit this, I learned the hard way)
└── package.json
Story generation took 14 seconds. The UI looked like a government form. There was no error handling — if the AI failed, the page just... sat there.
But my wife used it. My daughter got her Biscuit the Cloud Dragon story. And three friends tried it that night.
That's all Step 1 needs to do. Prove the idea breathes.
Your action: Ship something in 48 hours. Broken is fine. Invisible is not. Vercel gives you:
- Auto-deploy on every
git push - Preview URLs for every branch (share with friends for feedback)
- Serverless API routes (instant backend, no server setup)
- Free SSL, edge caching, analytics
- Zero configuration required
Step 2: Measure Before You Move — Find Your Real Bottleneck
Week two. I shared the app on a WhatsApp group. Parents in Jaipur, Bangalore, Delhi tried it.
The feedback was unanimous: "It's cool but... it takes forever."
Forever, in parent-with-sleepy-child terms, means anything over 5 seconds.
I checked Vercel's dashboard. Function execution: 3.2 seconds. That seemed fine — most of it was waiting for the LLM API. But users were experiencing 6-8 seconds total. Where was the extra time going?
The problem nobody warns you about: Vercel's serverless functions run in one region. Usually iad1 (US East, Virginia). My users were in India. Every request was doing this:
Phone (Mumbai) → Vercel Edge (closest node) → Function (Virginia, USA)
→ OpenAI API (US) → back to Virginia → back to Edge → back to Mumbai
That's 14,000 km. Each way. Multiple times.
 The numbers that convinced me to move — 13x improvement in Time to First Byte
The numbers that convinced me to move — 13x improvement in Time to First Byte
How I measured it (do this before you "fix" anything):
// Add to your API route — dead simple timing
export async function POST(req) {
const start = Date.now()
const body = await req.json()
console.log(`[Parse] ${Date.now() - start}ms`)
const story = await generateStory(body)
console.log(`[LLM] ${Date.now() - start}ms`)
return Response.json({ story })
// Check: vercel logs --follow
}
Then open Chrome DevTools → Network tab from a real user's location (use a VPN to simulate, or just ask your friend in another city to screen-record).
My actual numbers:
| What I measured | From my laptop (Dehradun) | From user's phone (Jaipur) | |----------------|--------------------------|---------------------------| | DNS + Connection | 20ms | 120ms | | TTFB (Time to First Byte) | 380ms | 620ms | | Full story response | 3.8s | 6.1s | | Images/audio loading | 60ms | 180ms |
The 240ms difference in TTFB? That's pure geography. Physics. Light traveling through undersea cables. You cannot fix this with better code. You fix it by moving your server closer to your users.
The rule: If your users are more than 3,000 km from your server region, you have a latency tax you're paying on every single request. For India-based users on a US-hosted backend, that tax is 200-300ms per round trip.
Step 3: Move Your API to AWS Lambda (In the Right Region)
Here's the mindset shift that changed everything for me:
Vercel = where you develop. AWS = where you produce.
You're not "leaving" Vercel. You're promoting your backend to infrastructure you control. Think of it like this: Vercel is your rehearsal studio. AWS is the stage.
What moves to AWS:
- API routes → AWS Lambda (same serverless model, but you pick the region)
- Static files → S3 (story images, audio narrations)
- Delivery → CloudFront (AWS's CDN, 400+ global edge locations)
What stays on Vercel:
- Your frontend (Next.js pages)
- Dev/staging preview deployments
- The "try things fast" workflow you love
The Lambda setup (simpler than you think):
# One-time setup
brew install aws-cli aws-sam-cli
aws configure # enter your IAM credentials
# Create your project
sam init --runtime nodejs20.x --name mysleepytale-api --app-template hello-world
Your function handler — this is literally your Vercel API route, repackaged:
// functions/generate-story/index.mjs
import { generateWithLLM } from './llm-client.mjs'
export const handler = async (event) => {
const { theme, characterName, mood } = JSON.parse(event.body)
const story = await generateWithLLM({
prompt: `Create a 2-minute bedtime story about ${characterName},
themed around ${theme}, with a ${mood} tone.
Keep it gentle. End with the character falling asleep.`
})
return {
statusCode: 200,
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': 'https://mysleepytale.com',
'Cache-Control': 'public, max-age=3600, s-maxage=86400'
},
body: JSON.stringify({
story: story.text,
audioUrl: story.audioUrl,
imageUrl: story.imageUrl
})
}
}
The key line — deploy to Mumbai:
sam deploy \
--region ap-south-1 \
--stack-name mysleepytale-prod \
--capabilities CAPABILITY_IAM \
--resolve-s3
ap-south-1 = Mumbai, India. My users are in India. That 280ms network hop? Now it's 18ms.
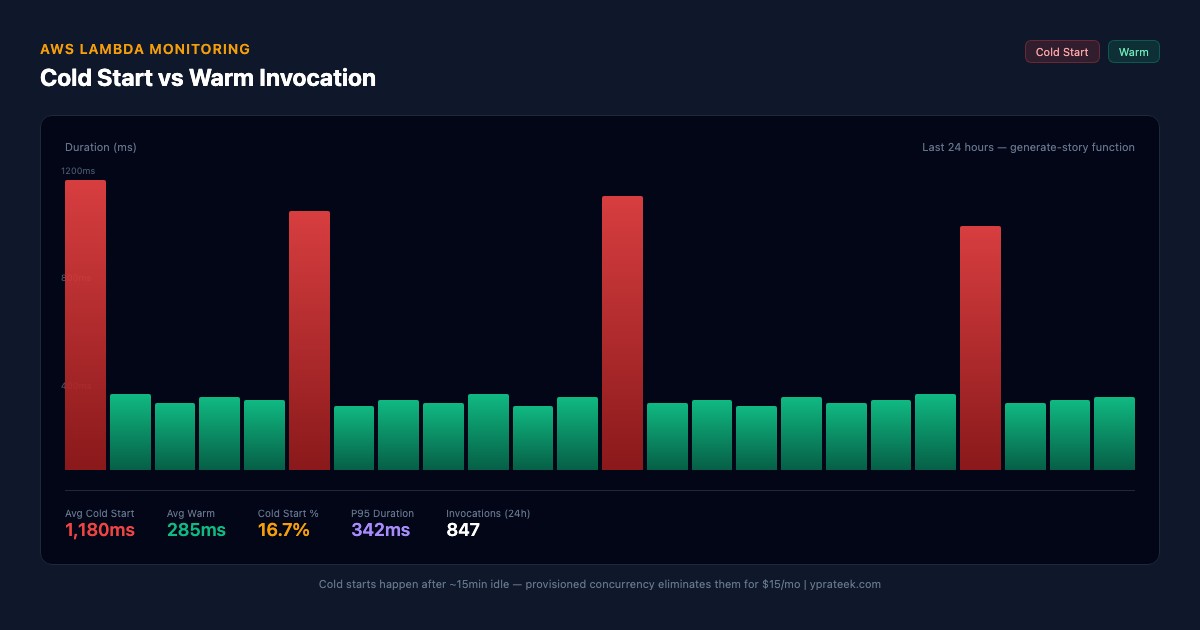 Cold starts are the silent killer of serverless UX — keep functions warm with provisioned concurrency if your budget allows
Cold starts are the silent killer of serverless UX — keep functions warm with provisioned concurrency if your budget allows
Pro tip for new builders: Lambda cold starts (the delay when your function hasn't run in a while) can add 1-2 seconds. For a bedtime story app, that's the difference between a child staying calm and losing interest. Solutions:
- Keep your deployment package small (fewer dependencies = faster init)
- Use provisioned concurrency for critical paths (costs ~$15/month)
- Or just accept it for v1 — optimize later
Step 4: Put CloudFront in Front of Everything
CloudFront is the cheat code.
Think of it as a global network of mini-servers, each storing copies of your content. When a user in Delhi requests a story that someone in Mumbai already generated — CloudFront serves it from Delhi's edge in 8ms. Never touches your Lambda. Never crosses the internet. Already there, waiting.
The architecture after this step:
Parent's Phone (Delhi, 10:02 PM)
↓
CloudFront Edge (Delhi, 12ms away)
↓
[Cache HIT?] → Story served instantly (8ms) ✓ Child happy
↓
[Cache MISS?] → API Gateway → Lambda (Mumbai, 18ms)
↓
LLM API → Generate story (2.8s)
↓
Cache response at edge
↓
Return to user (total: 3.1s first time)
↓
Next user with same params? → 8ms ✓
 CloudFront's 400+ edge locations mean your content is always physically close to your users
CloudFront's 400+ edge locations mean your content is always physically close to your users
Setting it up:
1. Create S3 bucket for static assets:
# Story illustrations, audio narrations, app assets
aws s3 mb s3://mysleepytale-assets-prod --region ap-south-1
# Upload with proper cache headers
aws s3 sync ./public/stories s3://mysleepytale-assets-prod/stories \
--cache-control "public, max-age=31536000" \
--content-type "image/webp"
2. Create CloudFront distribution:
You can do this via AWS Console (easier for first time) or CLI:
# Point CloudFront to your API Gateway + S3
aws cloudfront create-distribution \
--origins '[
{
"DomainName": "mysleepytale-api.execute-api.ap-south-1.amazonaws.com",
"Id": "api-origin",
"CustomOriginConfig": {
"HTTPSPort": 443,
"OriginProtocolPolicy": "https-only"
}
},
{
"DomainName": "mysleepytale-assets-prod.s3.ap-south-1.amazonaws.com",
"Id": "assets-origin",
"S3OriginConfig": { "OriginAccessIdentity": "" }
}
]' \
--default-cache-behavior '{
"TargetOriginId": "api-origin",
"ViewerProtocolPolicy": "redirect-to-https",
"CachePolicyId": "658327ea-f89d-4fab-a63d-7e88639e58f6"
}'
3. Connect your domain:
# Add CNAME record pointing your domain to CloudFront
# api.mysleepytale.com → d1234abcdef.cloudfront.net
The magic of cache headers: Remember that Cache-Control header in your Lambda response? CloudFront reads it. s-maxage=86400 means: "Cache this at the edge for 24 hours." Same story request from any user in that region? Served from edge. Zero Lambda invocations. Zero cost.
Step 5: Wire It All Together — Dev to Prod Pipeline
Here's the full picture. This is what MySleepyTale looks like today — the system that serves stories to real parents every night:
The final production architecture — CloudFront distributes globally, Lambda handles logic, S3 stores assets
┌─────────────────────────────────────────────────────────────┐
│ PRODUCTION (AWS) │
├─────────────────────────────────────────────────────────────┤
│ │
│ User (India, 10 PM, cranky toddler) │
│ ↓ │
│ CloudFront CDN (Delhi/Mumbai/Bangalore edge) │
│ ├── Static assets (S3) → images, audio, fonts │
│ └── API requests → API Gateway → Lambda (ap-south-1) │
│ ↓ │
│ LLM API Call │
│ (story generation) │
│ ↓ │
│ Response cached at edge │
│ │
├─────────────────────────────────────────────────────────────┤
│ STAGING (Vercel) │
├─────────────────────────────────────────────────────────────┤
│ │
│ Every PR → auto preview URL │
│ Share with beta testers → collect feedback │
│ Merge to main → triggers AWS deployment │
│ │
├─────────────────────────────────────────────────────────────┤
│ CI/CD (GitHub Actions) │
├─────────────────────────────────────────────────────────────┤
│ │
│ on push to main: │
│ 1. Run tests │
│ 2. sam build && sam deploy (Lambda) │
│ 3. aws s3 sync (static assets) │
│ 4. aws cloudfront create-invalidation (bust cache) │
│ │
└─────────────────────────────────────────────────────────────┘
The daily workflow:
- Idea or bug → create branch → code locally
- Push branch → Vercel auto-deploys preview → share URL with wife for testing ("does the story sound weird?")
- Iterate → push again → new preview URL instantly
- Happy with it → merge PR to
main - GitHub Actions fires → deploys Lambda, syncs S3, busts CloudFront cache
- Users get update → next request picks up the new version, globally
The GitHub Actions workflow (simplified):
# .github/workflows/deploy-prod.yml
name: Deploy to AWS Production
on:
push:
branches: [main]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: aws-actions/setup-sam@v2
- name: Build & Deploy Lambda
run: |
sam build
sam deploy --no-confirm-changeset --no-fail-on-empty-changeset
- name: Sync Static Assets to S3
run: aws s3 sync ./public s3://mysleepytale-assets-prod --delete
- name: Invalidate CloudFront Cache
run: |
aws cloudfront create-invalidation \
--distribution-id ${{ secrets.CF_DISTRIBUTION_ID }} \
--paths "/*"
The Final Numbers (Because Numbers Don't Lie)
After three weekends of migration work, here's where MySleepyTale landed:
| Metric | Before (Vercel-only) | After (AWS Production) | Improvement | |--------|---------------------|------------------------|-------------| | TTFB (Indian users) | 620ms | 45ms | 13.7x faster | | Story generation (first request) | 6.1s | 3.1s | 2x faster | | Cached story load | N/A | 8ms | instant | | Image/audio delivery | 180ms | 22ms | 8x faster | | Monthly cost | $0 (free tier) | ~$12/month | worth every rupee | | Deployment time | 90 seconds | 4 minutes | slightly slower, but automated |
The $12/month is mostly S3 storage for audio files + Lambda invocations. CloudFront's free tier covers the first 1TB of transfer. For a side project serving a few hundred parents, that's more than enough.
What I'd Tell Myself Three Months Ago
Don't overthink it.
The biggest mistake I see first-time builders make isn't choosing the wrong stack. It's never shipping because they're researching the "right" stack.
Here's the cheat sheet. Print this. Tape it above your monitor:
| Step | What to Do | When to Do It | |------|-----------|---------------| | 1 | Ship on Vercel | Weekend 1 (just get it live) | | 2 | Measure real user latency | After 10+ real users | | 3 | Move API to Lambda (right region) | When latency hurts UX | | 4 | Add CloudFront | Same time as step 3 | | 5 | Set up CI/CD pipeline | Once deploys become manual pain |
You don't need AWS on Day 1. Vercel will carry you through your first 1,000 users. It's the fastest path from "I have an idea" to "people are using my thing." Respect that.
But when your users are on the other side of the planet — when they're on a phone, on patchy WiFi, at 10 PM with a toddler who's one slow-loading screen away from a meltdown — that's when you graduate.
MySleepyTale went from "interesting weekend project" to "parents actually rely on this every night" when I stopped optimizing code and started optimizing geography.
The tech isn't the product. The speed is.
Build fast. Ship faster. Then make it fly.
Currently building MySleepyTale — AI-powered bedtime stories that generate in seconds, not minutes. If you're building your first app and hitting walls, DM me. I've hit every wall there is, from hostels in the Himalayas to serverless functions at midnight.
Follow me for more on shipping AI products, cloud architecture for indie builders, and the occasional story about building things in places where you probably shouldn't.